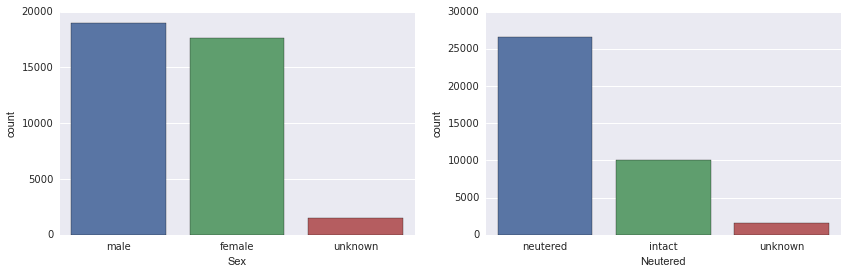
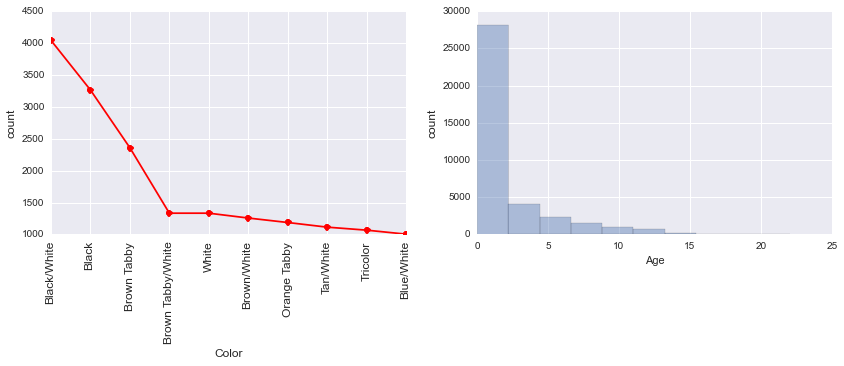
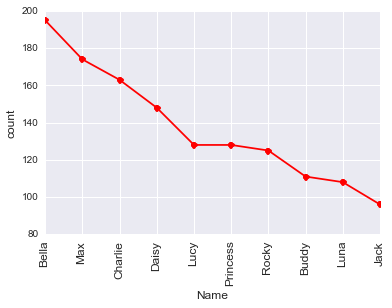
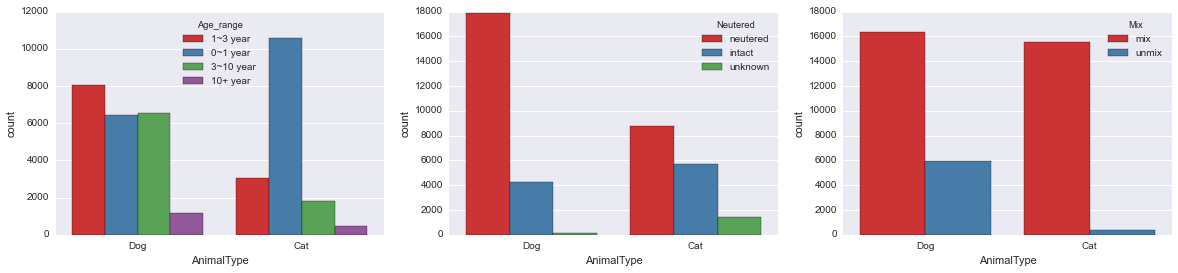
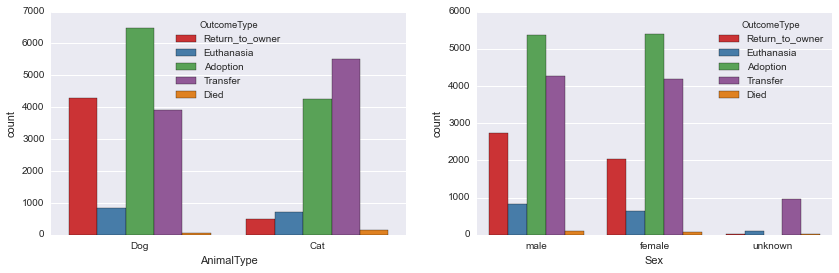
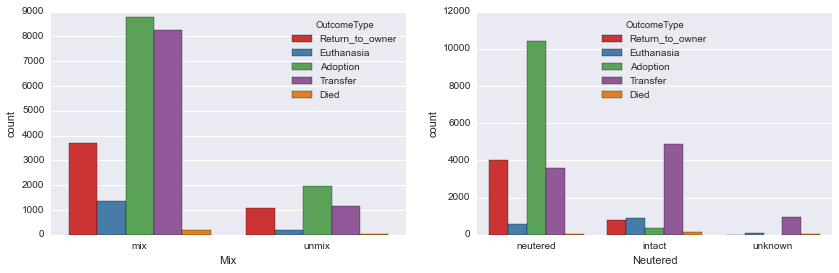
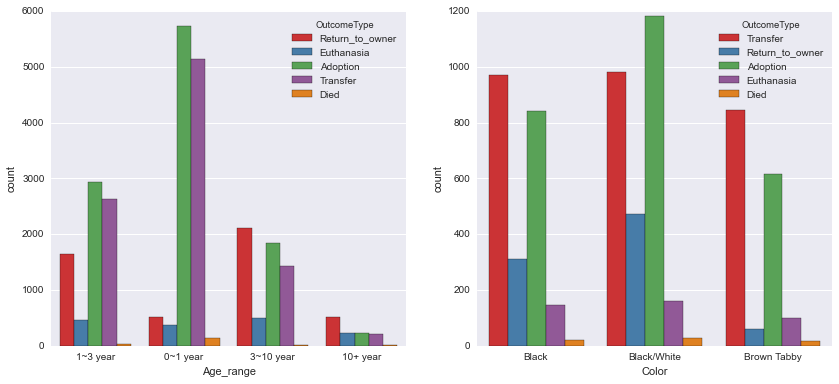
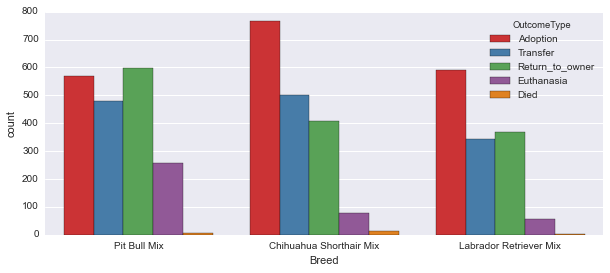
平稳性
平稳性是大多数时间序列分析问题中的一个大前提,而通常我们讨论的都是弱平稳,需要满足以下几个条件:
1)在任意时间点变量的均值函数是一个常数
2)在任意时间点变量的方差函数是一个常数
3)在任意两个时间点的自协方差函数只与两点时间间隔有关,而与这两点具体的时间点无关
典型的平稳时间序列:白噪声 $N(t)$
典型的非平稳时间序列:random walk($R(t) = \sum_1^t N(i)$,方差随时间改变)
如果时间序列不满足平稳性,可以做N阶差分运算。
自相关
时间序列的自相关性,从字面上就可以看出来,就是看这个序列平移一段距离后与这个原始信号有多相似。
有点类似于卷积,但符号刚好相反。
|
|
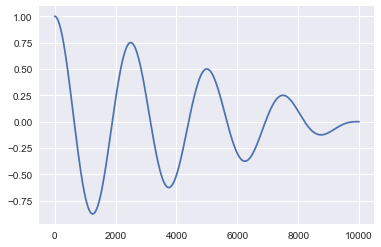
一般来说,平稳时间序列的自相关函数会随时间快速衰减。
其实本来是想看看关于时间序列分析的资料来应用到KDD CUP 2017的比赛上,而且之前天池上O2O口碑商家销量预测也是一个类似的时间序列问题。但是反复琢磨了一下,题目最终的预测只是在rush hours中的一两组数据,真正关于时序的信息可能真的用不大,而且之前口碑比赛里也有相应的反应,像ARIMA这种模型效果并不理想,所以下一步可能会考虑模式匹配的方法来做。