引言
两天前南大周志华教授在arXiv上放了一篇文章:Deep Forest: Towards An Alternative to Deep Neural Networks。国内机器学习界瞬间爆炸,业内著名非著名人士纷纷前来解读,有说即将取代DNN的,有说其实没什么新玩意就是那么回事的。我们这里只阐述这个model的基本结构和原理,不做任何评价(个人认为在相同资历和学术水平上才真正有资格去评价,反正我是没资格)。
Architecture
首先,Deep Forest,换一种叫法,gcForest(multi-Grained Cascade forest),可以翻译为多粒度级联随机森林。通俗的来讲就是把若干个随机森林合并起来作为类似于神经网络中的一个layer,然后将这些layer串联起来,形成一个基于组合随机森林的、相对deep的模型。通过这个描述,模型的主体结构就已经基本形成了,如下图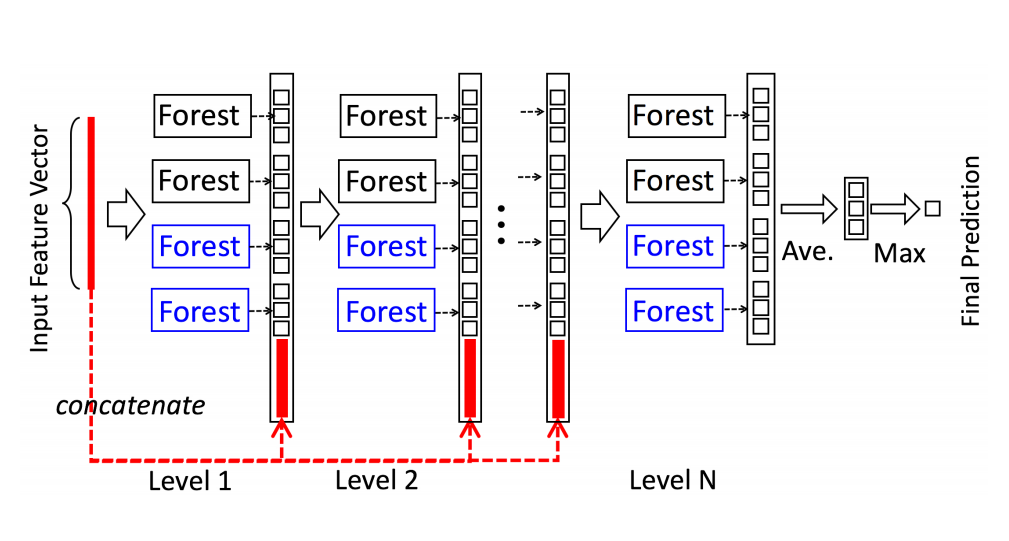
这里level就是layer的概念,而我们发现Forest有黑色和蓝色两种,其中黑色代表传统意义上的随机森林,即每次选择sqrt(#Features)数量的特征作为候选特征进行分裂;蓝色代表“完全随机森林”,其中每个森林中包含1000棵树,每棵树随机选择特征进行节点的分裂使树一直生长到叶节点只包含同类样本或小于是个样本。因为随机森林本质上就一种ensemble method,而每一个layer又引入了若干个两种随机形式的随机森林,因此在layer层面上可以认为是“ensemble of ensemble”。
现在具体到一个layer,如下图,假设现在是个三分类问题,那么每个随机森林的输出都是这三个类别的概率值,因此对于任何一个样本而言,在每一个layer的每一个forest输的都是3维的向量,如果每一个layer有4个forest,那么在这个layer上就输出43维的新特征灌到下一个layer里。注意,如果不是最后一层,那么每一层接收的特征还要加上raw feature,也就是第N+1层比第N层多出了43个特征。如果是最后一层,就不再接收原始特征,把上一层的输出结果做平均再取最大值,作为最后的prediction。还有一点很重要,也是区别于DNN的最显著因素,就是gcForest每一层都是监督学习,都利用到了label的信息,而非像DNN一样只在最有一层才是有监督而进行误差传播。这样的好处就是可以每向后训练一层就用validation set评估一下accuracy和loss,因为每一层的输出结果都是可解释的,都可以拿来当做预测得分,因此如果训练N+1层时验证效果提高不大或有降低时,可以自适应的终止训练。在这点上DNN必须在训练前就指定layer的层数,相当于变相多了一个超参数。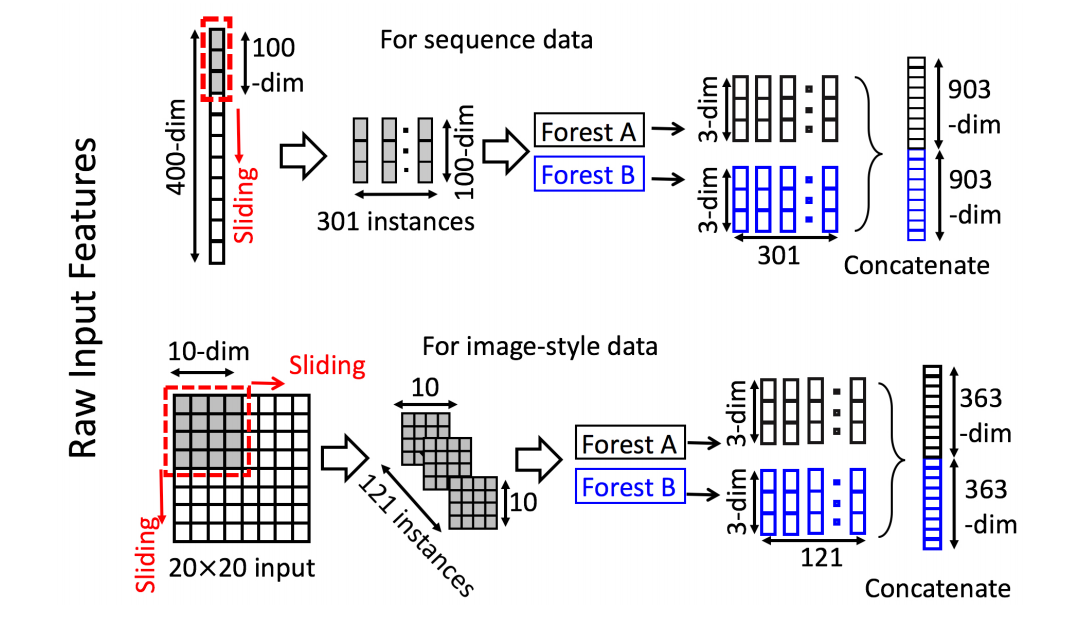
Multi-Grained Scanning
这算是论文的另一个亮点吧,主要描述了如何由原始数据生成样本和特征,依然还是先看下图。对于序列数据,假设特征是400维,现在我们用一个100维的滑动窗口(实际上窗口也是可变的,并不是只有一个窗)来做window-slide(比较类似于1D-convolution),每滑动一次生成100维向量就作为一个新的样本,这里相当于把原始数据做了滑动拆分,最终形成301个100维特征的子样本。接下来把这些样本灌到Deep Forest的第一层,一个Random Forest为301个子样本生成3个新特征,一个Complete Random Forest也为301个子样本生成3个新特征,然后再将这些特征做一个concat,这样一来一个真正的400维特的样本在第一层输出的高阶特征就是23301维。后面的训练过程就和上面写的一样,一层接一层,直到模型精度改善不明显的时候就终止。而对于图像数据也同理,只不过window-slide由一维变为二维(类似于2D-convolution),不再赘述。整体流程如下图,画的非常明白。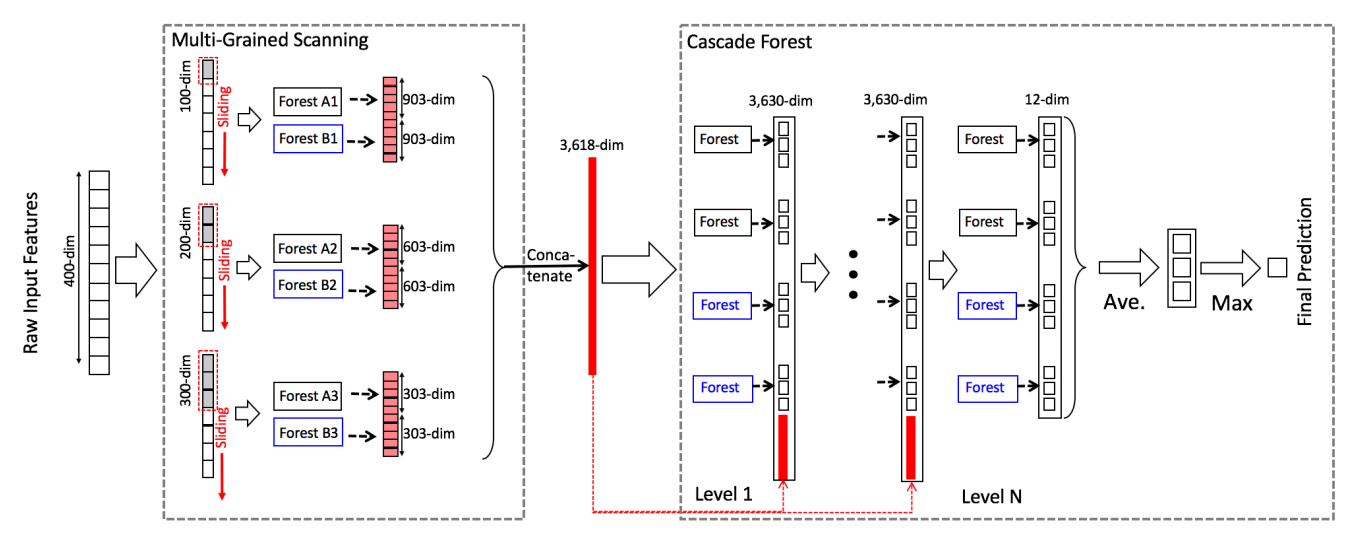
DF vs DNN
再来看DF与对标对象DNN的参数对比,也是文章比较骄傲的一点。在训练DNN时候我们需要指定一大堆超参数,最常见的比如layer数、neuron数、dropout rate、batch size等等。但DF完全不用考虑这些超参,只用默认的参数就很好了。
Performance
不多说,直接上图。
总的来说,这些评估结果都是基于小数据集的,在大数据集上还没测试过。但不可否认的是,相对于DL来讲效率还是要快不少,而且也没用到GPU资源。要知道现在普遍大公司里计算资源已经不是瓶颈了,而是如何把这些复杂的算法在线或是移动端应用起来,所以在这种趋势下,文章提出的这种方法还是极有意义的。