Deep & Cross Network for Ad Click Predictions,是四位在谷歌的中国人放出的一篇文章。题目也一目了然,是用复杂网络结构做CTR预估的,与2016年谷歌的wide and deep model非常相似,于是利用课余时间梳理并简单的实现了一下。
原理
Input
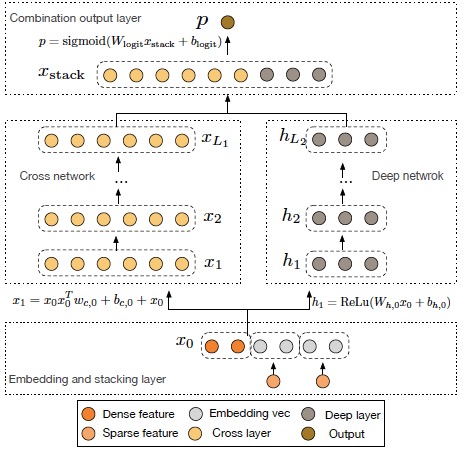
我们从wide and deep model切入,不论是wide侧还是deep侧,在输入端为embedding feature + cross feature + continous_feature。而这里就会存在一个小问题,在构造cross feature时,我们依然需要依靠hand-craft来生成特征,那么哪些分类特征做cross,连续特征如何做cross,都是需要解决的小麻烦。而来到了deep and cross model,则免去了这些麻烦,因为在输入层面,只有embedding column + continuous column,feature cross的概念都在网络结构中去实现的。
Cross Network
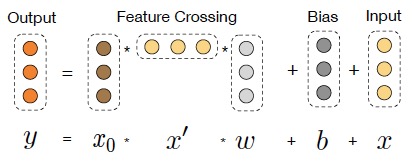
将输入的embedding column + continous column定义为$x_0$($x_0 \in R^d$),第$l+1$层的cross layer为
其中$w_l(w_l \in R^d)$和$b_l(b_l \in R^d)$为第$l$层的参数。这么看来,Cross这部分网络的总参数量非常少,仅仅为$layers * d * 2$,每一层的维度也都保持一致,最后的output依然与input维度相等。另一方面,特征交叉的概念体现在每一层,当前层的输出的higher-represented特征都要与第一层输入的原始特征做一次两两交叉。至于为什么要再最后又把$x_l$给加上,我想是借鉴了ResNet的思想,最终模型要去拟合的是$x_{l+1} - x_{l}$这一项残差。
Deep Network
这部分就不多说了,和传统DNN一样,input进来,简单的N层full-connected layer的叠加,所以参数量主要还是在deep侧。
Output
Cross layer和Deep layer出来的输出做一次concat,对于多分类问题,过一个softmax就OK了。
实现
在实现上主要利用了Keras的Functional API Model,可以比较方便的自定义layer,数据集利用了文章中提到的Forest coverType数据,layer数及nueron数也都根据文章中写死,但有所不同的是文章中貌似没有对categorical feature做embedding ,而数据集中有一个cardinality为40的categorical feature,所以代码里对这个变量做了embedding,embedding维度也按文章中的公式指定。其他超参也所剩无几,几乎都是些weights的初始化方法。最后放上生成的网络结构及代码。

|
|