原理部分
书接上回,FM模型无论是对于交叉特征的捕捉能力上,还是在工业界大规模数据下的运用方面上,都具有出色的表现。因此,在深度学习火热的大背景下,各种基于FM模型和神经网络模型相结合的方法也开始频频出现。这里要说的是SIGIR 2017和IJCAI 2017的两篇文章Neural Factorization Machine和Attentional Facotrization Machine,无一例外,它们都是在FM的基础上衍生出与深度学习相关的研究。由于两篇文章的是同一团队所著,所以工作有重叠和改进部分,前一篇网络结构相对简单,因此本文主要针对Attentional Facotrization Machine展开,但也会在其中涉及Neural Factorization Machine。不仅如此,作者也同样给出了开源实现,源码解析也会在此基础上进行(Neural FM and Attention FM)。
FM模型虽然存在了所有可能的二阶特征交叉项,但本质上,并不是所有的特征都是有效的,比如一个垃圾特征a和一个牛逼特征b做交叉可能会起到一些作用,但a和垃圾特征c再做交叉基本上不会有任何作用,因此Attentional Facotrization Machine解决的问题主要就是——利用目前比较流行的attention的概念,对每个特征交叉分配不同的attention,使没用的交叉特征权重降低,有用的交叉特征权重提高,加强模型预测能力。原始的FM模型,如果忽略一阶项,可以表示为
这里我们可以把$v_i$理解为特征$x_i$的feature embedding,而上式中交叉项的表达为embedding向量的内积,因此输入的$y$直接就为标量,不需要再次的映射;但是这种内积操作如果变换为哈达玛积的操作(element-wise product)$(v_i \odot v_j) x_i x_j$,这样从Neural Network的角度去看,每个特征都交叉之后上层就变成了一个embedding layer,然后再对这个layer做一次sum pooling和映射,便可以得到输出值,即
至此,Neural Factorization Machine中所描述的已经叙述完毕,就是这么简单。而来到了Attention这篇,思想一致,只是在embedding layer的sum pooling时为每个embedding加上对应的attention,也就是权重,即
其中$\alpha$通过对embedding空间做了一次encoding并标准化得到,
另外,由于这种attention的方式对训练数据的拟合表达更充分,但也更容易过拟合,因此作者除了在loss中加入正则项之外,在attention部分加入了dropout。具体模型结构如下图:
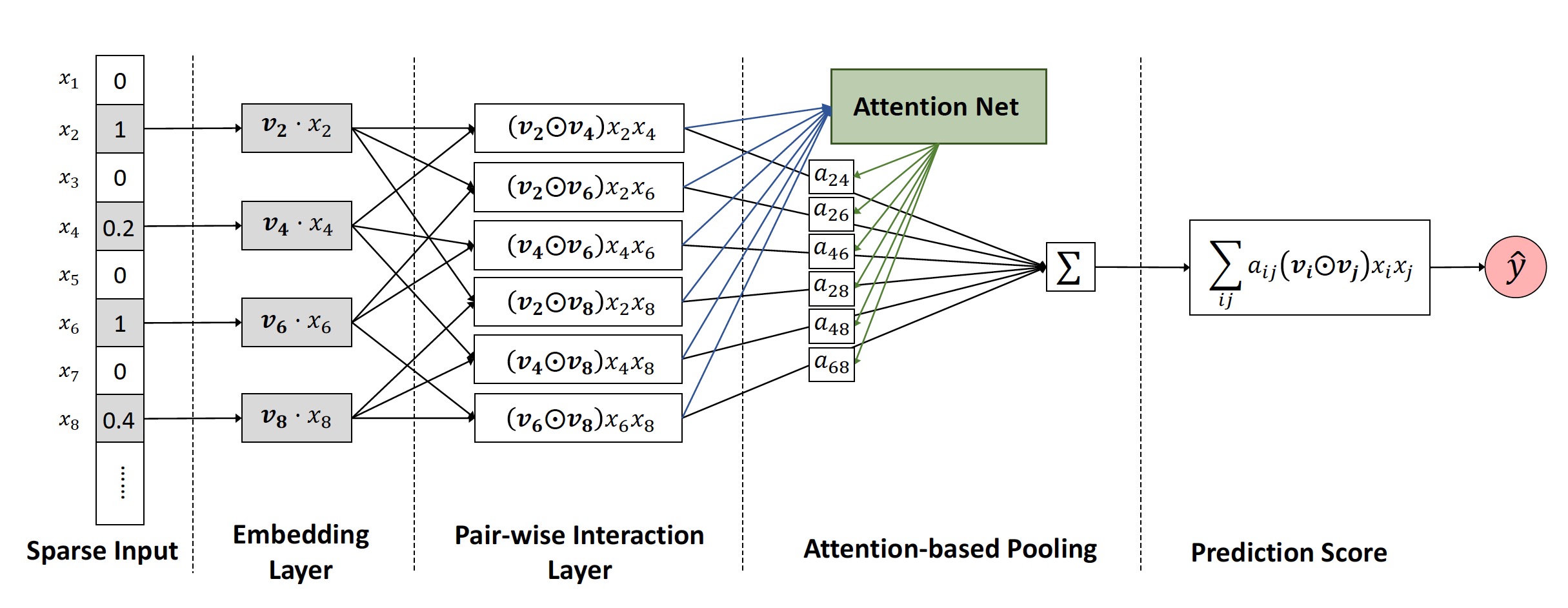
作者在Frappe和MovieLens数据集上进行了实验,AFM的表现beat掉了所有fine tuned的对比模型(LibFm、HOFM、Wide&Deep、DeepCross)。而且,使用这套框架的传统FM也要比LibFM的效果好,原因之一在于dropout的引入降低了过拟合的风险,第二在于LibFM在迭代优化时使用的是SGD方法,对每个参数的学习步长一致,很容易使后期的学习很快的止步,而Adagrad的引入使得学习率可变,因此性能更加优良。另外,attention的引入,一方面加速了收敛速度,另一方面也具有对交叉特征的可解释性(因为就是权重),类似于特征重要性。
代码部分
截取了一部分关键代码,解析在注释中体现
|
|