最近在做站内新用户推荐相关的项目,由于新用户历史行为相对较少,传统的neighborhood method和factor method models上对于user profile的利用少之又少,而如果当做一个传统的二分类问题,即预测购买/不购买,同样也存在相似的问题——特征不足,model能力上限有瓶颈,因此想着挖掘一下会话的time series pattern,从而变成一个基于session的预测问题,主要参考了ICLR 2016的一篇文章,个人感觉这篇文章可以算是利用RNN做基于session推荐比较早期的方法,而且作者也开源了基于theano的实现,后续一些improved版本,包括网易在考拉上的session推荐实践也都借鉴了这篇文章的一些思想,接下来对这篇文章进行一个简单的梳理。
文章中解决的问题是:给定一个session中的item点击流(click streaming events),来预测这个点击流后的下一个点击会是什么item,并最终由目标item完成推荐。需要注意的是,作者虽然用到了recsys 2015的数据来做model evaluation,但实际上并没有用到购买数据,因此这篇文章所解决的问题只是通过session的item序列模式挖掘可能感兴趣的item,并不是最终会发生购买行为的item。按照这个模型结构来看,输入数据就是某个session的当前状态,即前N个item click sequences所携带的序列信息,输出就是当前session第N+1个item。所以在一个点击流中的一个特定点击事件的网络结构可以表达为如下图所示,输入为已点击item的one-hot编码,经过一层embedding层来进行降维,再通过多层GRU(Gated Recurrent Unit)单元,最后通过一个前馈映射层来输出下一个item的likelihood。
简要描述一下GRU的原理(这里作者用GRU的原因是在GRU、LSTM和传统RNN单元中发现GRU效果最好)。传统RNN的hidden state数学表达为
也就是某一个时间点上的hidden state与当前时间点的输入和上一个时间点的hidden state有关,并且是二者线性组合的形式,但当时间序列过长时,会面临严重的梯度消失问题,而GRU和LSTM由于网络结构的变化可以有效的解决传统RNN中的时间维度梯度消失问题。其中GRU引入了update gate $z_t$和reset gate $r_t$的概念,两个gate控制当前时刻输入和上一时刻的记忆信息哪部分需要保留,哪部分需要丢弃,表达形式一致,分别表示为
而输出的hidden state为
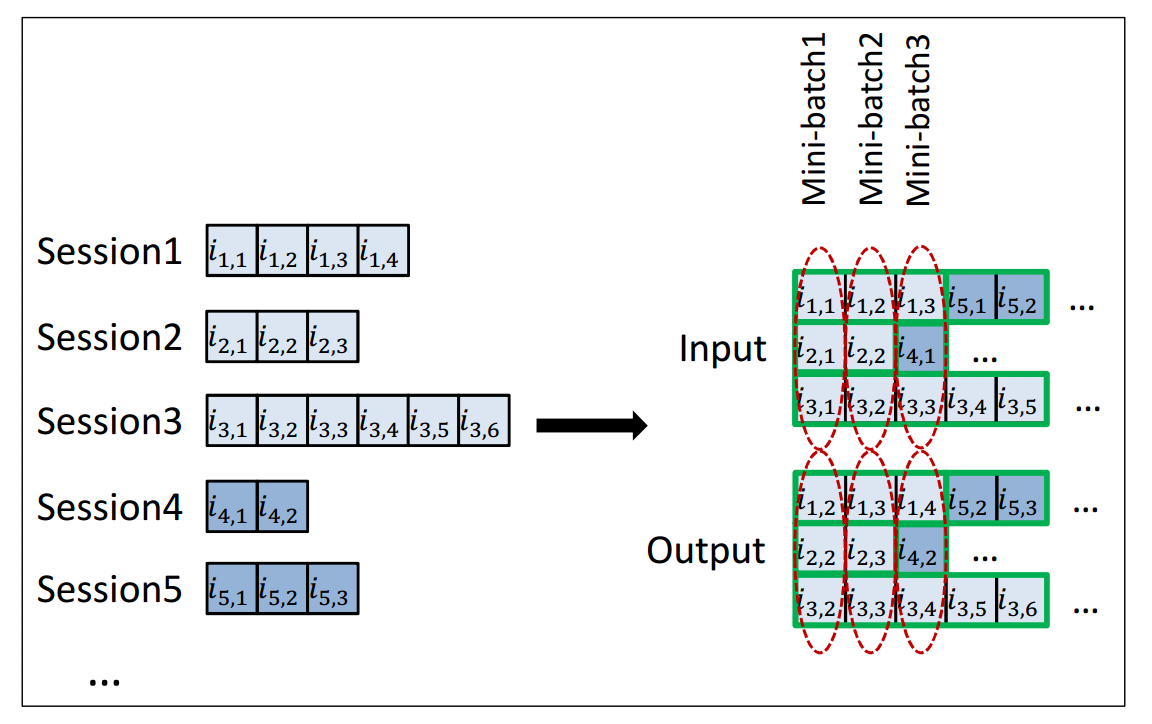
在构造数据集时,文章采用了session后补齐再划分mini-batch的方法(如下图)。具体来讲,就是当一个session结束时,用一个新的session接到当前session的末尾,当这个事件发生时,hidden state就被重新置零。
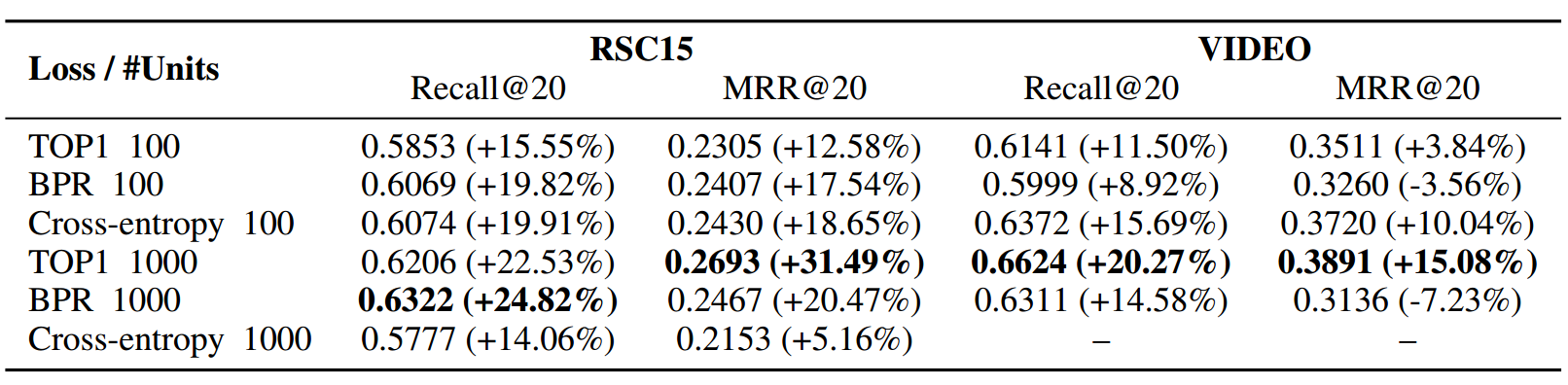
虽然可以把上述问题作为一个多分类问题,但最后文章在实验中发现用cross-entropy做loss在100个左右hidden units时效果不错,但一旦units数量增大效果就不如ranking loss的形式,因此采用了pairwise ranking loss作为损失函数,并分别列举了BPR(Bayesian Personalized Ranking)和TOP1,其中某一个特定session中的一个点击预测loss为
,这里$\hat {r}_{S,j}$为第$j$个negative sample item的score,$\hat {r}_{S,i}$为postive sample item的score,值得注意的是这里对负样本做了一定程度的负采样,以消除一些用户可能感兴趣但并没有展示商品的影响。
实验在Recsys 2015数据集和另一个视频点击数据集上进行,以MRR@20和Recall@20作为指标评估,分别比较了不同mini-batch大小、dropout大小、learning-rate大小和momentum和loss形式下的效果,并与一些传统流行的推荐算法baseline进行对比,均有提升,细节不详谈,有兴趣的可以自己去看一下。