Google在去年6月份在arxiv上放出了”Wide & Deep Learning for Recommender Systems”这篇文章,应用场景是Google Play上App安装预测,线上效果提升显著(相比较于Wide only和Deep only的model)。与此同时,Google也开源了这一模型框架并将其集成在Tensorflow的高级封装Tflearn中,今年开年的谷歌开发者大会上也专门有一个section是讲wide and deep model的,作者的意图也很明显,一方面推广tensorflow,另一方面是显示模型的强大。
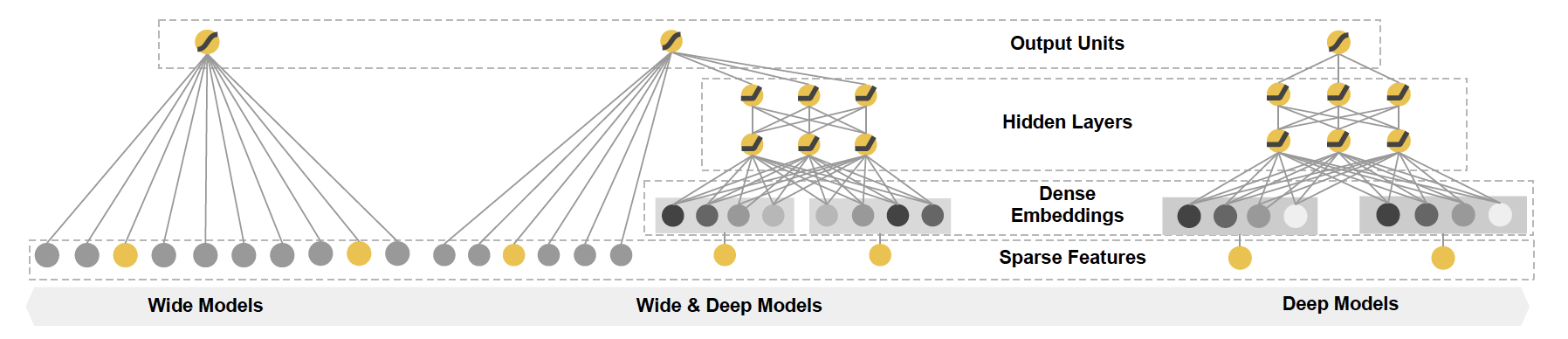
通读文章后,发现其实模型的基本原理很简单,就是wide model + deep model。分别来讲,wide model就是一个LR,在特征方面除了原始特征外还有分类特征稀疏表达后的交叉特征,例如将分类特征做完one-hot后再进行cross product。个人理解,这里一方面是利用类似于FM模型原理来增强分类特征的特征交互(co-occurrence),另一方面是利用LR对高维稀疏特征的学习能力,而作者把wide model所具备的能力称为“memorization”;而deep model则是一个DNN,特征上除了原始特征还增加了分类特征的embedding,这个embedding在模型中属于独立的一层,embedding后的向量也是通过不断迭代学习出来的。将高维稀疏分类特征映射到低维embedding特征这种方式有助于模型进行“generalization”。Memerization和Generalization这两个概念中文还真没找到特别合适的诠释,如果非要翻译一下,我觉得应该是推理和演绎,一个是通过特征交互关系来训练浅层模型,另一个则是通过特征在映射空间中的信息训练深层模型。
模型结构采用joint的方式而非传统的ensemble方式。如果是ensemble方式,那么这两个模型就针对label进行单独训练,然后再加权到一起;而joint方式则是将这两个模型的输出加起来,然后再针对label进行联合训练。这样的好处是在train model的时候可以同时最优化两个model的参数,而且两个model可以起到互相补充的作用。下面的公式也很好的解释了wide and deep model的结构原理,即两个model的output在通过sigmoid函数之前把结果相加,然后再经过sigmoid实现分类。这里$x$指原始特征,$\phi(x)$分别表示wide模型的cross product feature和deep模型的embedding feature,而$w_{deep}$则泛指DNN各层weights和bias集合表示。
最终模型在离线评测上效果并不明显,但在在线评测上提升还算显著。前几天在电梯里听到广告部同事说他们也在搞这个模型,离线效果提升了10%+,但在线serving技术上目前比较头疼,但也不知道具体是什么指标提升了10%+。但在我们团队内部客户拉新预测问题的离线应用上,同样的数据效果只和xgboost持平。另外,官方提供的tutorial原生代码并不能很好的应用于大数据量,于是进行了改写,读取数据方式变成了队列读取,也是参考了stackoverflow上的一些反馈。核心就是wide_and_deep函数,cross product的实现方式是直接在预处理数据时对分类特征进行字符串拼接,然后再做one-hot,相对contrib中crossed_column的实现方式略显复杂,但以个人能力也只能先这样做,日后再去探索。另外,由于目前团队业务只涉及线下模型,因此对于模型的线上更新并没有太多关注,但大的技术框架来看应该也是用tf serving的方式实现。
|
|